如何建立會自動更新與刪除的 RAG 資料管線:5 步驟實作指南
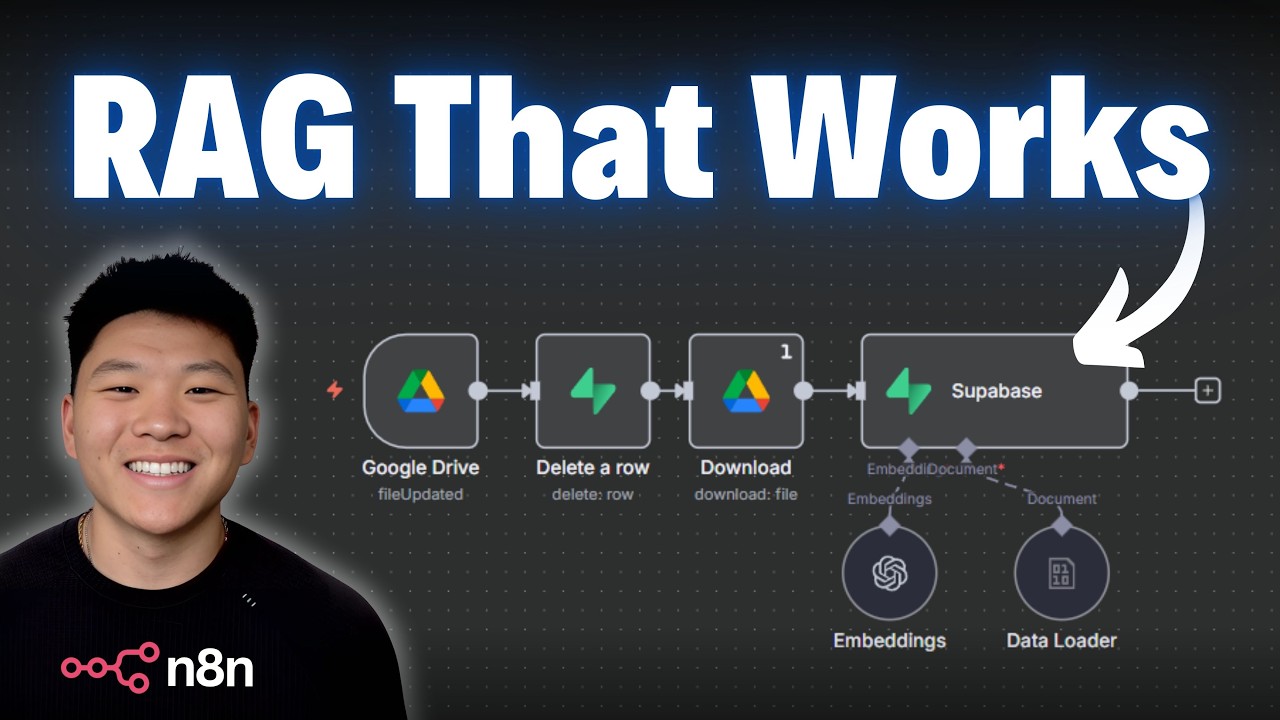
在這部由 Nate Herk 所示範的實作教學中,他示範如何為 RAG(Retrieval-Augmented Generation)系統建立一條自動化資料管線,確保當你在 Google Drive 新增、更新或刪除 PDF 檔案時,向量資料庫(影片中稱為「Superbase」)會同步新增、更新或刪除對應的向量資料。核心議題是「資料的正確性與可預測性」——正如他所言:「predictability is your best friend」,沒有穩定且可驗證的資料來源,任何 AI agent 都無法給出可靠答案。
Nate 強調:建立一個供所有 agent 共用的知識庫,其前提是「知識是準確且最新的」。若資料「雜亂、過時或分散」,agent 將無法產出正確答案。因此必須設計自動化的 RAG 管線,不斷檢查向量資料庫的正確性與一致性。影片中他以實務例子闡明:「當你把 PDF 丟到 Google Drive,系統要把它放進向量資料庫;當你更新或刪除該檔案,資料庫也要同步更新或刪除。」
RAG 資料管線的三階段與四個關鍵要素
Nate 把資料管線分為三個步驟: - 原料(Raw material):輸入的原始檔案或資料來源(例如 YouTube URL、PDF、CSV)。 - 處理流程(Processing line):轉成可 ingest 的資料(擷取文字、時間戳、去重、打上 metadata、chunk 與 embedding)。 - 終端位置(Destination):向量資料庫或關聯式資料庫(影片示例使用 Supabase/Superbase 作為向量存放地)。
此外有四個必須考慮的要素: 1. 觸發器(Trigger):「what actually starts the process」——例如新郵件、Google Sheet 新列、檔案上傳或某條件達成。 2. 輸入(Inputs):「你需要知道資料會以何種格式進來」——PDF、CSV、圖片還是純文字? 3. 處理(Processing):「清理、去重、標注 metadata、拆 chunk、產生 embeddings」。 4. 儲存(Storage):「把處理完的文件放入向量資料庫或其他儲存層」。
實作案例(1)——新增檔案:Google Drive → Supabase
Nate 的第一個流程是:當新檔案放入 Google Drive 指定資料夾(範例資料夾名 = "rag")時,自動把檔案放入向量資料庫。關鍵步驟與設定包括: - 觸發器:使用 Google Drive 的「on changes involving a specific folder」,並設定為「file created」。其範例動作:「we're watching for a new file being created in this folder」。 - 下載檔案:使用 Download by ID。若是 Google Doc,需「add conversion」把 doc 轉為 PDF(以 binary 形式輸入)。 - 資料庫上傳(Supabase vector store):資料 loader 改為接收 binary;加入 metadata 兩個欄位:file_name(範例為 "policy and FAQ document")與 date(timestamp),以利後續比對與刪除。 - Embedding:選用 OpenAI 的 embedding 模型,影片範例為「text-embedding-3-small」,此模型需與資料庫使用的 embedding 模型一致。 - 結果驗證:上傳後出現「5 items」被插入(代表文件被切成 5 個 chunk/向量)。可用一個簡單 agent 詢問文件內容,範例如:「what is our shipping policy?」得到回答(直接從向量檢索出): "Orders are processed within one to two business days. Standard shipping takes 3 to seven business days."
實作案例(2)——更新檔案:先刪除舊向量,再上傳新向量
當檔案在 Google Drive 更新(Trigger 設為「file updated」)時,必須把舊有向量刪除以避免資料不一致。Nate 的做法如下: - 先用 Google Drive trigger(on changes involving a specific folder,watch = "file updated")。 - 在 Supabase 使用「delete a row」節點刪除對應 rows。刪除條件以 metadata 中的 file_name 為鍵,表達式示例為:metadata->>file_name LIKE 'policy and FAQ document'。Nate 說明:「你可以用 file ID 或 file name 來當作唯一識別」。 - 執行刪除後,示例刪掉了原先的「5 items」,向量資料庫因此清空舊資料。 - 再下載(轉 PDF)並重新上傳新檔案(同新增流程),最終向量再次出現(新 metadata 顯示 store_name 從 "tech haven" 改為 "green grass"),以驗證更新成功。Nate 範例中反覆測試並確認 agent 回應內容也反映了新資料(agent 回答 store name 為 "green grass")。
處理重複輸出與執行次數:設定「Execute only once」
在流程測試時,Nate 發現刪除 rows 後 Google Drive 的節點會返回多筆同樣的輸出(因為 Supabase 回傳 5 items),導致後續節點被重複執行。解法是針對該節點設定「Execute only once」,避免重覆處理,確保流程穩定。這個細節在實務上能避免重複上傳或重複刪除造成的不一致。
處理檔案刪除:回收站(recycling bin)作為替代方案
Nate 指出 Google Drive 的 webhook/trigger 並未提供「file deleted」的直接選項;因此採取「回收站監控」作為替代: - 新建一個資料夾(範例名 = "recycling bin"),並把觸發器設為「file created」但監控此 recycling bin。 - 當使用者把檔案從原資料夾移到回收站時,該事件會觸發(因為在回收站發生了 file created),流程只需執行 Supabase 的刪除邏輯(以 metadata->>file_name 為條件刪除)。 Nate 說明:「這是一個 band-aid fix,但可行」,目的在於示範管線思維,而非最完美的產品化實作。
關鍵技術設定與數據(需突顯)
- 資料庫:Supabase(影片中稱為 Superbase),表格範例名為 documents,表中包含 embedding 欄位。
- Chunk 數量:影片範例中上傳結果顯示「5 items」,表示原始文件被切分為 5 個 chunk 進行嵌入。
- Embedding 模型:OpenAI text-embedding-3-small(需同資料庫所用模型一致)。
- Metadata 欄位:至少建立 file_name(或 file_id,作為唯一識別)與 date(timestamp)以利版本管理與刪除操作。
- 觸發器策略:使用 folder-level triggers(on changes involving a specific folder)可同時處理多個檔案,避免為每個檔案單獨設 trigger。
驗證流程與 Agent 測試
Nate 實作了一個簡單 agent,連接向量資料庫後,直接向 agent 詢問文件內容以驗證檔案是否被成功 ingest。範例回答摘錄: "Orders are processed within one to two business days. Standard shipping takes 3 to seven business days." 這證明了整條管線從檔案上傳 → 處理 → 向量化 → 檢索都能串通運作。
注意事項與擴充方向
- 可預測性很重要:先明確你的輸入類型(PDF、Word、Excel、影像、文字),再針對不同類型建處理分支(Nate:「predictability is your best friend」)。
- 唯一識別:使用 file_id 比較可靠,但 file_name 可讀性高;任選一種且在 metadata 中保持一致即可。
- 刪除策略:影片採回收站監控作為 workaround;若要產品化,建議探查 Drive API 或 webhook 是否可提供更直接的 deleted event,或維護一份檔案狀態表(例如 Google Sheet)做雙向比對。
- 優化向量化:Nate 表示本次示範以簡化為主,未深入討論最佳 chunk 長度、語言偵測、去噪或不同文件類型的特殊處理;生產環境應考量這些細節。
結論與行動建議
- 建立 RAG 管線的核心是「觸發器、輸入、處理、儲存」四要素,以及保證資料可預測與可驗證。
- 在 metadata 中保存唯一識別(file_id 或 file_name)與 timestamp(date),可實現「更新即刪除舊向量、再上傳新向量」的正確流程。
- 面對無法直接偵測刪除事件的情況,可採用「監控回收站」作為實作上的可行替代方案。
- 測試時注意避免節點被重複執行(例如設定 execute only once),以免出現重複上傳或刪除失誤。
- 若要擴展至多種檔案類型(Word、Excel、圖片等),應在觸發器與處理流程中加入類型分流與對應的處理邏輯。
參考資料(原始教學影片):https://www.youtube.com/watch?v=5uw1wE6niGc



